聊一聊:Python和Golang的垃圾回收
本文最后更新于:2025年1月12日 凌晨
在计算机科学中,垃圾回收(英语:Garbage Collection,缩写为GC)是指一种自动的存储器管理机制。当某个程序占用的一部分内存空间不再被这个程序访问时,这个程序会借助垃圾回收算法向操作系统归还这部分内存空间。垃圾回收器可以减轻程序员的负担,也减少程序中的错误。垃圾回收最早起源于LISP语言。[1][2]目前许多语言如Smalltalk、Java、C#、Go和D语言都支持垃圾回收器。

GC作为现代编程语言的自动内存管理机制,专注于两件事:1. 找到内存中无用的垃圾资源 2. 清除这些垃圾并把内存让出来给其他对象使用。GC彻底把程序员从资源管理的重担中解放出来,让他们有更多的时间放在业务逻辑上。但这并不意味着码农就可以不去了解GC,毕竟多了解GC知识还是有利于我们写出更健壮的代码。
常见的垃圾回收算法
引用计数:为每个对象维护一个引用计数,当引用该对象的对象销毁时,引用计数 -1,当对象引用计数为 0 时回收该对象。
- 代表语言:Python、PHP、Swift
- 优点:对象回收快,不会出现内存耗尽或达到某个阈值时才回收。
- 缺点:不能很好的处理循环引用,而实时维护引用计数也是有损耗的。
标记-清除:从根变量开始遍历所有引用的对象,标记引用的对象,没有被标记的进行回收。
- 代表语言:Golang(三色标记法)、Python(辅助)
- 优点:解决了引用计数的缺点。
- 缺点:需要 STW,暂时停掉程序运行。
分代收集:按照对象生命周期长短划分不同的代空间,生命周期长的放入老年代,短的放入新生代,不同代有不同的回收算法和回收频率。
- 代表语言:Java、Python(辅助)
- 优点:回收性能好
- 缺点:算法复杂
Python的垃圾回收机制
官方文档中关于Pyhton内存管理的描述:
Python 内存管理的细节取决于实现。 Python 的标准实现 CPython 使用引用计数来检测不可访问的对象,并使用另一种机制来收集引用循环,定期执行循环检测算法来查找不可访问的循环并删除所涉及的对象。
gc模块提供了执行垃圾回收、获取调试统计信息和优化收集器参数的函数。但是,其他实现(如 Jython 或 PyPy ),)可以依赖不同的机制,如完全的垃圾回收器 。如果你的Python代码依赖于引用计数实现的行为,则这种差异可能会导致一些微妙的移植问题。
简而言之:Python默认采用的垃圾收集机制是引用计数法,为了解决对象的循环引用问题,Python引入了标记-清除和分代回收两种GC机制。
引用计数
Python语言默认采用的垃圾收集机制是『引用计数法 Reference Counting』,该算法最早George E. Collins在1960的时候首次提出,50年后的今天,该算法依然被很多编程语言使用。
『引用计数法』的原理是:每个对象维护一个ob_ref字段,用来记录该对象当前被引用的次数,每当新的引用指向该对象时,它的引用计数ob_ref加1,每当该对象的引用失效时计数ob_ref减1,一旦对象的引用计数为0,该对象立即被回收,对象占用的内存空间将被释放。它的缺点是需要额外的空间维护引用计数,这个问题是其次的,不过最主要的问题是它不能解决对象的“循环引用”,因此,也有很多语言比如Java并没有采用该算法做来垃圾的收集机制。
什么是循环引用?A和B相互引用而再没有外部引用A与B中的任何一个,它们的引用计数虽然都为1,但显然应该被回收,例子:
1 | |
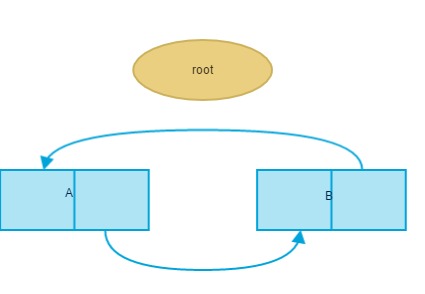
在这个例子中程序执行完del语句后,A、B对象已经没有任何引用指向这两个对象,但是这两个对象各包含一个对方对象的引用,虽然最后两个对象都无法通过其它变量来引用这两个对象了,这对GC来说就是两个非活动对象或者说是垃圾对象,但是他们的引用计数并没有减少到零。因此如果是使用引用计数法来管理这两对象的话,他们并不会被回收,它会一直驻留在内存中,就会造成了内存泄漏(内存空间在使用完毕后未释放)。为了解决对象的循环引用问题,Python引入了标记-清除和分代回收两种GC机制。
标记清除
『标记清除(Mark—Sweep)』算法是一种基于追踪回收(tracing GC)技术实现的垃圾回收算法。它分为两个阶段:第一阶段是标记阶段,GC会把所有的『活动对象』打上标记,第二阶段是把那些没有标记的对象『非活动对象』进行回收。那么GC又是如何判断哪些是活动对象哪些是非活动对象的呢?
对象之间通过引用(指针)连在一起,构成一个有向图,对象构成这个有向图的节点,而引用关系构成这个有向图的边。从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象。根对象就是全局变量、调用栈、寄存器。

在上图中,我们把小黑圈视为全局变量,也就是把它作为root object,从小黑圈出发,对象1可直达,那么它将被标记,对象2、3可间接到达也会被标记,而4和5不可达,那么1、2、3就是活动对象,4和5是非活动对象会被GC回收。
标记清除算法作为Python的辅助垃圾收集技术主要处理的是一些容器对象,比如list、dict、tuple,instance等,因为对于字符串、数值对象是不可能造成循环引用问题。Python使用一个双向链表将这些容器对象组织起来。不过,这种简单粗暴的标记清除算法也有明显的缺点:清除非活动的对象前它必须顺序扫描整个堆内存,哪怕只剩下小部分活动对象也要扫描所有对象。
分代回收
分代回收是一种以空间换时间的操作方式,Python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python将内存分为了3“代”,分别为年轻代(第0代)、中年代(第1代)、老年代(第2代),他们对应的是3个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。同时,分代回收是建立在标记清除技术基础之上。分代回收同样作为Python的辅助垃圾收集技术处理那些容器对象。
内存泄露
实际上python在日常使用的过程中出现内存泄漏的情况比较少见,关于Python的内存泄露,值得注意的一点:CPython退出时为什么不释放所有内存
当Python退出时,从全局命名空间或Python模块引用的对象并不总是被释放。 如果存在循环引用,则可能发生这种情况 C库分配的某些内存也是不可能释放的(例如像Purify这样的工具会抱怨这些内容)。 但是,Python在退出时清理内存并尝试销毁每个对象。
如果要强制 Python 在释放时删除某些内容,请使用
atexit模块运行一个函数,强制删除这些内容。
在一些Python实现中,以下代码(在CPython中工作的很好)可能会耗尽文件描述符:
1 | |
实际上,使用CPython的引用计数和析构函数方案, 每个新赋值的 f 都会关闭前一个文件。然而,对于传统的GC,这些文件对象只能以不同的时间间隔(可能很长的时间间隔)被收集(和关闭)。
如果要编写可用于任何python实现的代码,则应显式关闭该文件或使用 with 语句;无论内存管理方案如何,这都有效:
1 | |
Goalng的垃圾回收机制
Go 语言采用的是标记清除算法。并在此基础上使用了三色标记法和写屏障技术,提高了效率。
标记清除收集器是跟踪式垃圾收集器,其执行过程可以分成标记(Mark)和清除(Sweep)两个阶段:
- 标记阶段 — 从根对象出发查找并标记堆中所有存活的对象;
- 清除阶段 — 遍历堆中的全部对象,回收未被标记的垃圾对象并将回收的内存加入空闲链表。
标记清除算法的一大问题是在标记期间,需要暂停程序(Stop the world,STW),标记结束之后,用户程序才可以继续执行。为了能够异步执行,减少 STW 的时间,Go 语言采用了三色标记法。
三色标记算法将程序中的对象分成白色、黑色和灰色三类。
- 白色:不确定对象。
- 灰色:存活对象,子对象待处理。
- 黑色:存活对象。
垃圾回收优化
写屏障(Write Barrier):前面说过STW目的是防止GC扫描时内存变化而停掉goroutine,而写屏障就是让goroutine与GC同时运行的手段。虽然写屏障不能完全消除STW,但是可以大大减少STW的时间。
写屏障类似一种开关,在GC的特定时机开启,开启后指针传递时会把指针标记,即本轮不回收,下次GC时再确定。
GC过程中新分配的内存会被立即标记,用的并不是写屏障技术,也即GC过程中分配的内存不会在本轮GC中回收。
辅助 GC(Mutator Assist):为了防止内存分配过快,在 GC 执行过程中,GC 过程中 mutator 线程会并发运行,而 mutator assist 机制会协助 GC 做一部分的工作。
流程如下图:
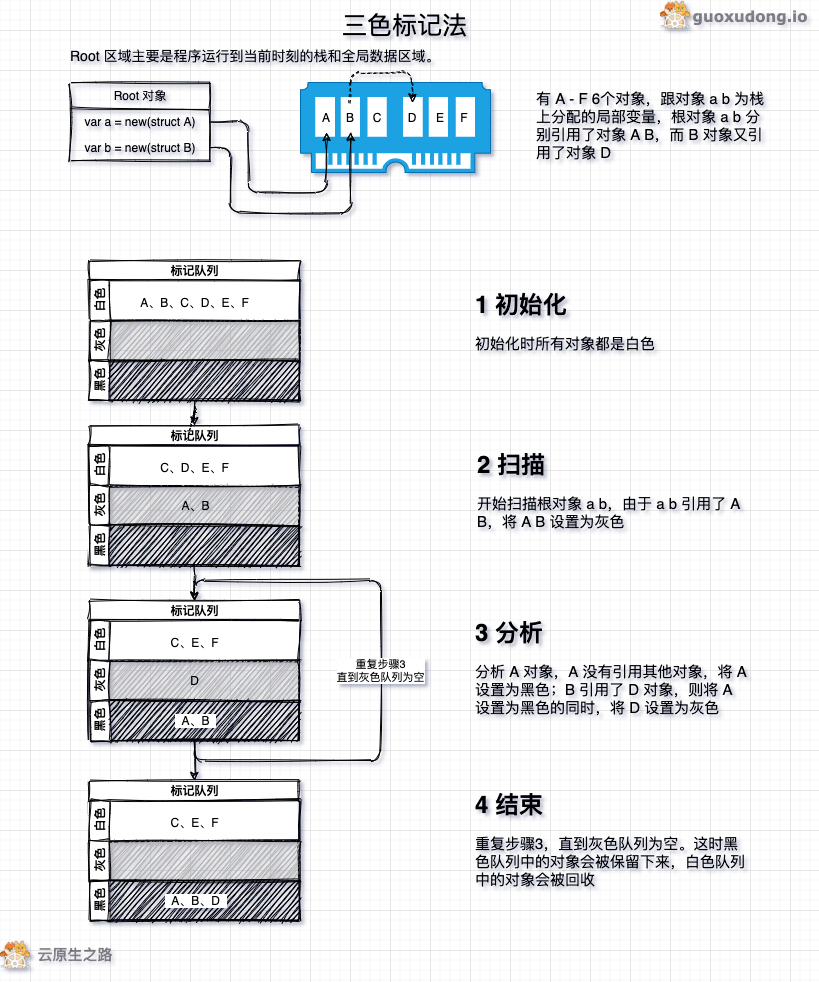
一次完整的 GC 分为四个阶段:
- 1)标记准备(Mark Setup,需 STW),打开写屏障(Write Barrier)
- 2)使用三色标记法标记(Marking, 并发)
- 3)标记结束(Mark Termination,需 STW),关闭写屏障。
- 4)清理(Sweeping, 并发)
go的内存逃逸
逃逸分析的作用:
- 逃逸分析的好处是为了减少GC的压力,不逃逸的对象分配在栈上,当函数返回时就回收了资源,不需要GC标记清除。
- 逃逸分析完后可以确定哪些变量可以分配在栈上,栈的分配比堆快,性能好(逃逸的局部变量会分配在堆上,而没有发生逃逸的则由编译器分配到栈上)
- 同步消除,如果你定义的对象在方法上有同步锁,但在运行时,却只有一个线程在访问,此时逃逸分析后的机器码,会去掉同步锁运行
逃逸总结
- 栈上分配内存比在堆中分配内存有更高的效率
- 栈上分配的内存不需要GC处理
- 堆上分配的内存使用完毕会交给GC处理
- 逃逸分析的目的是决定内存分配到堆还是栈
- 逃逸分析在编译阶段完成
常见的内存逃逸场景:
- 在方法内把局部变量指针返回 局部变量原本应该在栈中分配,在栈中回收。但是由于返回时被外部引用,因此其生命周期大于栈,则溢出。
- 发送指针或带有指针的值到 channel 中。 在编译时,是没有办法知道哪个
goroutine会在channel上接收数据。所以编译器没法知道变量什么时候才会被释放。 - 在一个切片上存储指针或带指针的值。 一个典型的例子就是
[]*string。这会导致切片的内容逃逸。尽管其后面的数组可能是在栈上分配的,但其引用的值一定是在堆上。 - slice 的背后数组被重新分配了,因为 append 时可能会超出其容量( cap )。 slice 初始化的地方在编译时是可以知道的,它最开始会在栈上分配。如果切片背后的存储要基于运行时的数据进行扩充,就会在堆上分配。
- 在 interface 类型上调用方法。 在 interface 类型上调用方法都是动态调度的 —— 方法的真正实现只能在运行时知道。想像一个 io.Reader 类型的变量 r , 调用 r.Read(b) 会使得 r 的值和切片b 的背后存储都逃逸掉,所以会在堆上分配。
go的内存泄露
Go程序可能会在一些情况下造成内存泄漏。go101网站总结了各种内存泄漏的情况,我在这里简单罗列一下:
- 获取长字符串中的一段导致长字符串未释放
- 同样,获取长slice中的一段导致长slice未释放
- 在长slice新建slice导致泄漏
- goroutine泄漏
- time.Ticker未关闭导致泄漏
- Finalizer导致泄漏
- Deferring Function Call导致泄漏
参考资料
一些可能的内存泄漏场景:https://gfw.go101.org/article/memory-leaking.html